For a few years now, I’ve used Dolphin / Konqueror / Krusader for transferring files to or from my home server via SFTP. However when there were larger amounts to be transferred, I opened the shell and used rsync. That’s because I felt it was always somewhat slower with SFTP. I blamed it on the weak file server, on the network, or whatever.
Recently I again wanted to clean up my desktop’s home directory, where a bunch of raw or edited videos were sitting. All in all ~250 GiB. Because I wanted to sort the videos into different sub-directories on the server, I used Dolphin and SFTP once again. While I was watching the transfer, I began to doubt whether the network between my desktop and the home server was actually Gigabit, because I only saw 10-15 MiB/s. Quick check with rsync and scp: nope, 80+ MB/s is possible, just not with Dolphin.
That’s when I decided to get to the bottom of the issue. I discovered KDE bug 296526 – Dolphin is too slow when upload a file on a SSH server. It fit exactly what I was observing, even though it’s from 2012. That’s 14 years! I went on to read all the comments, and it became apparent that none of the users that had commented had spent the time to do a proper side-by-side comparison, and document it properly. So I took up that task and posted comment 40, where I wrote pretty much what I wrote here, but also the results of some tests that I had done with ‘libssh’. That’s the underlying library which kio-extras/sftp uses to interact with SSH/SFTP servers. And Dolphin / Konqueror / Krusader in turn use kio-extras/sftp to do SFTP transfers.
These tests showed very promising results: I could actually saturate my Gigabit link and transfer >750 Mbps. What I didn’t know at that time (September): I had tested a brand new version of libssh (0.11.0), released in August, that came with major changes. Namely a new async I/O API had been added. The transfers with Dolphin had still used libssh 0.10.x though.
Upon learning about these important changes, I opened a version bump request for libssh 0.11.0 in Gentoo’s bug tracker to make the Gentoo devs aware of this new libssh version. Fast forward two months, libssh 0.11.1 was available in Gentoo. I then erroneously tested with kio-extras linked against libssh 0.10.x (and thus disabled new async I/O API), even though I had 0.11.1 on my system. The reason was, that I hadn’t rebuilt kio-extras. That resulted in comment 45. A few minutes later I realized my error, rebuilt kio-extras (actually most of KDE, because an update was coming in anyway), and voilà: ~230 MiB/s or ~1840 Mbps (with peaks going >2 Gbps)! Hurray!
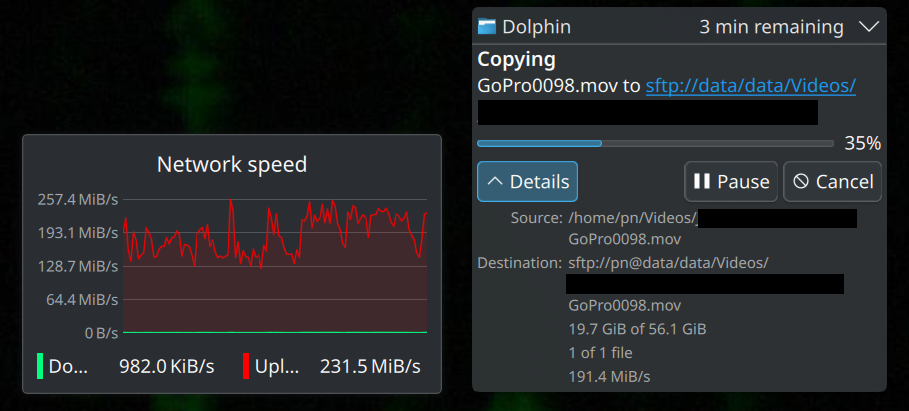
Side note: I had upgraded my network from Gigabit to 2.5 Gigabit in the meantime, otherwise that would obviously not be possible. But with the old libssh only around ~90 MiB/s or ~720 Mbps were possible over the same network, 2.5x slower than with the new libssh 0.11.x.
So, if you find that your SFTP transfers in KDE are slower than they should be, check which libssh version comes with your distribution. If it’s <0.11.0, you know you need to upgrade. With non-rolling binary distributions, you’ll probably have to wait a bit and then upgrade your whole distribution. For example Ubuntu will only get libssh 0.11.1 in “Plucky” aka version 25.04. For rolling distributions like Gentoo or Arch it’s already available.
This is probably the biggest single improvement to my Linux on the Desktop experience of the last years… hence this blog post 🙂